PostgreSQL: Replication & Failover
The Replication
Last post I started hands-on session with PostgreSQL installation on both docker and docker-compose, explored important PostgreSQL configuration and was able to mount persistent volumes and config files to customize PostgreSQL.
In this post I will setup a second PostgreSQL instance to setup a primaty and standby replication for PostgreSQL HA, by using some pg tools, last we will test failover by shut down primary and promot standby instance.
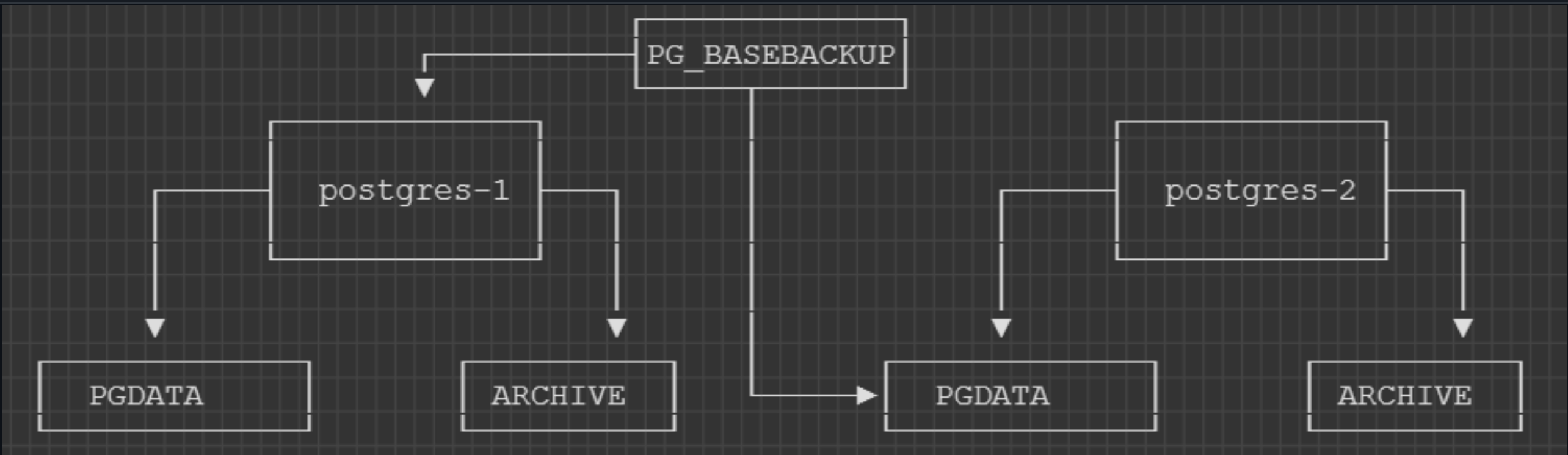
To achieve this, steps can be followed by:
- Setup docker network and Create Replication User in Primary instance
To establish PostgreSQL replication, it is necessary to set unique data volumes for data between instances and unique config files for each instance.
# create both primary and standby folders
root@ubt-server:~# mkdir postgres-1
root@ubt-server:~# mkdir postgres-2
# move previous post config file to postgres-1 and postgres-2
root@ubt-server:~# cp -r config/* postgres-1/config/
root@ubt-server:~# mv config/* postgres-2/config/
# create docker network so PostgreSQL containers on the same network
root@ubt-server:~/postgres-1/config# docker network create postgres
9891c6d9cd3bdbeea2fdfc2b287c868a0f67a3cec7f2939e1299cfb0ae293021
# run primary
root@ubt-server:~/postgres-1# docker run -it --rm --name postgres-1 \
--net postgres \
-e POSTGRES_USER=postgresadmin \
-e POSTGRES_PASSWORD=admin123 \
-e POSTGRES_DB=postgresdb \
-e PGDATA="/data" \
-v ${PWD}/postgres-1/pgdata:/data \
-v ${PWD}/postgres-1/config:/config \
-v ${PWD}/postgres-1/archive:/mnt/server/archive \
-p 5000:5432 postgres:15.0 \
-c 'config_file=/config/postgresql.conf'
2024-05-11 13:15:07.762 UTC [1] LOG: starting PostgreSQL 15.0 (Debian 15.0-1.pgdg110+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
2024-05-11 13:15:07.763 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
2024-05-11 13:15:07.763 UTC [1] LOG: listening on IPv6 address "::", port 5432
2024-05-11 13:15:07.764 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2024-05-11 13:15:07.766 UTC [63] LOG: database system was shut down at 2024-05-11 13:15:07 UTC
2024-05-11 13:15:07.768 UTC [1] LOG: database system is ready to accept connections
# create Replication User, chown postgres to access archive folder
root@ubt-server:~# docker exec -it postgres-1 bash
root@2bf6be3e4fa8:/# createuser -U postgresadmin -P -c 5 --replication replicationUser
Enter password for new role:
Enter it again:
root@2bf6be3e4fa8:/# chown postgres:postgres /mnt/server/archive
# add replication into configration file
root@ubt-server:~/postgres-1/config# vim pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD
# add replication user
host replication replicationUser 0.0.0.0/0 md5- Enable Write-Ahead Log, archive and Replication
Write-Ahead Log (WAL) is a PostgreSQL data integrity mechanism of writing transaction logs to file and does not accept the transaction until it has been written to the transaction log and flushed to disk. This ensures that if there is a crash in the system, that the database can be recovered from the transaction log.
So we need to add bellow lines into postgresql.conf to enable Write-Ahead Log and replica and archive
root@ubt-server:~/postgres-1/config# vim postgresql.conf
#replication
wal_level = replica
archive_mode = on
archive_command = 'test ! -f /mnt/server/archive/%f && cp %p /mnt/server/archive/%f'
max_wal_senders = 3- set up standby instance and validate replication here we need to use tool “pgbase_backup” to create standby instance by taking a primary instance base backup, type “replicationUser” passwd, then postgres-1 database will be back up into postgres-2 pgdata folder
root@ubt-server:~# docker run -it --rm --net postgres -v ${PWD}/postgres-2/pgdata:/data --entrypoint /bin/bash postgres:15.0
root@56e38636a87b:/# pg_basebackup -h postgres-1 -p 5432 -U replicationUser -D /data/ -Fp -Xs -R
Password: Now, we start the standby instance. See the log below. Postgres-2 is entering standby mode, ready to accept read-only connections, and starting streaming WAL from the primary.
root@ubt-server:~# docker run -it --rm --name postgres-2 --net postgres -e POSTGRES_USER=postgresadmin -e POSTGRES_PASSWORD=admin123 -e POSTGRES_DB=postgresdb -e PGDATA="/data" -v ${PWD}/postgres-2/pgdata:/data -v ${PWD}/postgres-2/config:/config -v ${PWD}/postgres-2/archive:/mnt/server/archive -p 5001:5432 postgres:15.0 -c 'config_file=/config/postgresql.conf'
PostgreSQL Database directory appears to contain a database; Skipping initialization
2024-05-11 14:25:21.008 UTC [1] LOG: starting PostgreSQL 15.0 (Debian 15.0-1.pgdg110+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
2024-05-11 14:25:21.008 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
2024-05-11 14:25:21.008 UTC [1] LOG: listening on IPv6 address "::", port 5432
2024-05-11 14:25:21.010 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2024-05-11 14:25:21.012 UTC [29] LOG: database system was interrupted; last known up at 2024-05-11 14:21:16 UTC
2024-05-11 14:25:21.017 UTC [29] LOG: entering standby mode
2024-05-11 14:25:21.026 UTC [29] LOG: redo starts at 0/5000028
2024-05-11 14:25:21.026 UTC [29] LOG: consistent recovery state reached at 0/5000100
2024-05-11 14:25:21.026 UTC [1] LOG: database system is ready to accept read-only connections
2024-05-11 14:25:21.034 UTC [30] LOG: started streaming WAL from primary at 0/6000000 on timeline 1- Test replication and failover
First, let us test the replication, by login to postgres-1, create a zack_customers table, then validating from postgres-2
# bash into postgres-1, create zack_customers table
root@ubt-server:~# docker exec -it postgres-1 bash
root@06dd98085df7:/# psql --username=postgresadmin postgresdb
psql (15.0 (Debian 15.0-1.pgdg110+1))
Type "help" for help.
postgresdb=# CREATE TABLE zack_customers (zackname text, z_customer_id serial, date_created timestamp);
CREATE TABLE
postgresdb=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------------+-------+---------------
public | zack_customers | table | postgresadmin
(1 row)
postgresdb=# \q
root@06dd98085df7:/# exit
exit
# bash into postgres-2, validate zack_customers table
root@ubt-server:~/postgres-2/pgdata# docker exec -it postgres-2 bash
root@b333ff290624:/# psql --username=postgresadmin postgresdb
psql (15.0 (Debian 15.0-1.pgdg110+1))
Type "help" for help.
postgresdb=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------------+-------+---------------
public | zack_customers | table | postgresadmin
(1 row)
postgresdb=# \q
root@b333ff290624:/# exit
exitnow we simulate failover by using loadbalancer tool “pgctl”, to shut down the primary instance, then promote the standby read-only instance into a read-write instance
# shut down the primary instance
root@ubt-server:~# docker rm -f postgres-1
postgres-1
# exec standby try to create a table zack_customers_2, get error as it's read-only
root@ubt-server:~# docker exec -it postgres-2 bash
root@b333ff290624:/# psql --username=postgresadmin postgresdb
psql (15.0 (Debian 15.0-1.pgdg110+1))
Type "help" for help.
postgresdb=# CREATE TABLE zack_customers_2 (zackname text, z_customer_id serial, date_created timestamp);
ERROR: cannot execute CREATE TABLE in a read-only transaction
postgresdb-# \q
# promote postgres-2 from standby to primary
root@b333ff290624:/# runuser -u postgres -- pg_ctl promote
waiting for server to promote.... done
server promoted
# exec to create table zack_customers_2, this time works
root@b333ff290624:/# psql --username=postgresadmin postgresdb
psql (15.0 (Debian 15.0-1.pgdg110+1))
Type "help" for help.
postgresdb=# CREATE TABLE zack_customers_2 (zackname text, z_customer_id serial, date_created timestamp);
CREATE TABLE
postgresdb=# \dt
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+---------------
public | zack_customers | table | postgresadmin
public | zack_customers_2 | table | postgresadmin
(2 rows)
postgresdb=# \q
root@b333ff290624:/# exit
exit
root@ubt-server:~# Conclusion
Now we are able to run a PostgreSQL primary and standby instances to test replication and failover, in the next blog I will discover how to depoly a single PostgreSQL on kubernetes.